What is Data Engineering? (For Your Mom)
There was a time when I didn't have to explain what I did for a living. I said I was a teacher and people instantly understood I meant.
Then I entered the analytics field. When people asked, "What do you do?", I would answer, "I'm a data engineer." The response was consistent: blank stares or confused looks.
The reaction is reasonable. Everyone's had a teacher, and teachers have been around since the dawn of time. A data engineer, on the other hand... well that title didn't exist 10 years ago. I fill the awkward silence after my answer with something like "I'm like a data plumber. I build data pipelines to move data from one place to another." This generates some laughs and moves the conversation to another topic, but it doesn't help a person understand what I do for a living.
Communicating my skillset is a barrier as I market my services. So here, I'll try to explain what data engineering is. In most simple terms, a data engineer writes code to move data from one place to another place, occasionally making changes to the data to make it more usable. This leads to the following questions:
- What data are we talking about?
- Why do we need to move data at all if it already exists somewhere?
- Why do you need code or automation when you can just manually move data around?
What are we talking about?
"Data" is a broad term. It can be interpreted in different ways given the experiences of the hearer. I like to think of data as a piece of information that represents something in reality. It can be the list of items in your last Amazon order, the employees at your company, or the voters who participate in an election. These pieces of information used to be written down on paper; today, data tends to be documented in electronic form. Data can be stored in many formats: Excel spreadsheets, databases, or simple text documents. Data can also be located anywhere from your laptop or smart phone all the way to a huge data center supporting "the cloud".
Moving sounds stressful
If we know data exist somewhere, why do we need to move it somewhere else and why do we need data engineers? Well, this is where we get into issues of data format, quality, and compatibility. It'd be nice if everyone agreed to use the same standard of data. Alas, that is not the case. The structure of data can vary. Some data are stored in tables while other data are stored in nested JSON structures:
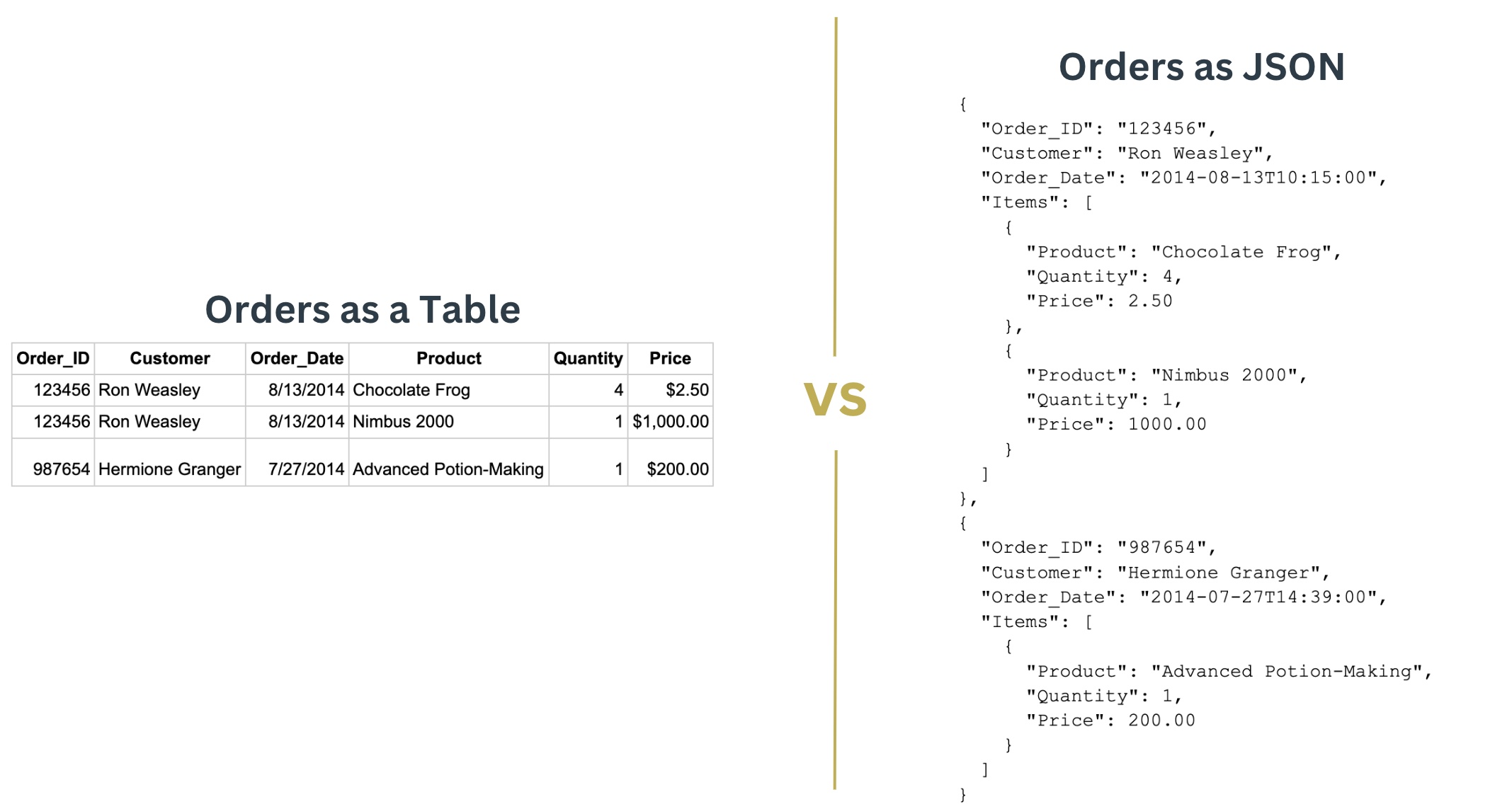
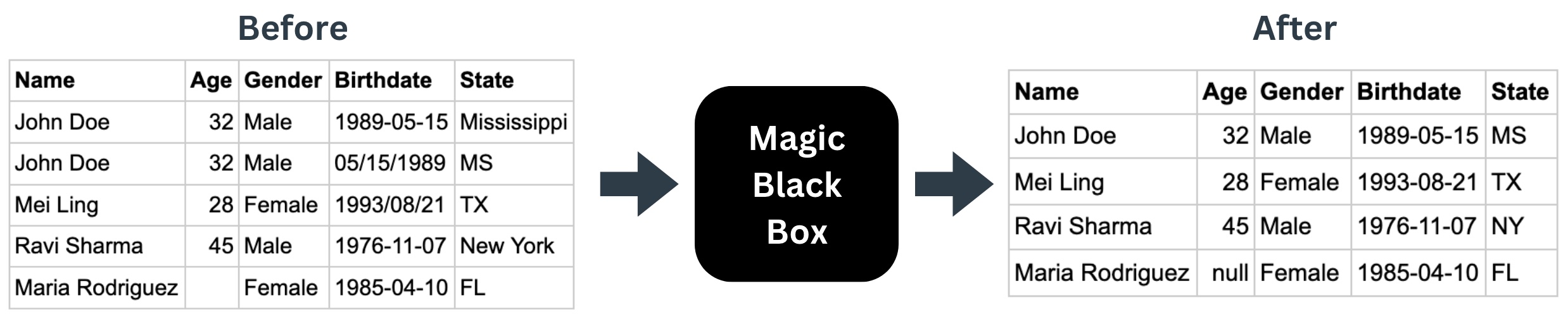
Even if the structure is the same, the "style" of the data can vary. For example, some data may list a US state by its full name while another data source defines states by their abbreviation (e.g. Mississippi vs MS). Even worse, some data sources have missing information (e.g. a person's address without their street name) or duplicate information (e.g. duplicate orders for the same customer).
These inconsistencies among data structures and potential quality issues can make data in their source locations difficult to use. Thus there is a need to restructure the data in a format that is usable. Data engineers typically do this by "copying" source data, making changes, and then storing the cleansed data in a new location. These steps are commonly called Extract, Transform, and Load, or ETL. Most often, data engineers will extract data from multiple locations and load cleansed data to a single destination, like a data warehouse. Others can then use the aggregated and cleansed data for their own needs.
Isn't coding overkill?
Now the final question: Why do data engineers use code or automation to work with data? After all, can't someone just manually download data from a source, make changes with a few clicks, and then upload the cleansed data somewhere else? While this manual approach is suitable, it is inefficient and introduces the risk of human error. For example, suppose someone needs to complete a series of data transformation tasks every morning. They may open an Excel sheet with original data, filter for a particular state, convert misspelled city names, save and close the file, and then transfer the file into a data warehouse. Again, this is feasible, but what if they forgot a step in this process one morning, or what if that person is sick and unavailable? Automated data pipelines are essentially pieces of code that replicate these steps and are run on a set schedule. While the initial writing and testing of the code may take some time, using such pipelines to automatically process data is far more efficient than a manual approach. Automated data pipelines are also scalable as one can have several data processes running in parallel. Most importantly, a coded pipeline ensures that each step is attempted consistently with every data refresh; this bypasses the risk of human error.
So that's basically it. A data engineer is someone who understands a business problem and writes code to move data from one location to another to address that problem. Embedded in this work is the need to transform and cleanse the original data into a format that's more helpful for others. They're the unsung heroes behind the data scientists building the cool machine learning models or the analysts making a ground-breaking discovery about the company's customer base. You know... a data plumber.
Do you have a collection of data that's unused? Or do you have a tedious, manual method of managing your data? Reach out to your local data plumber at KP Data Dev. We're happy to jump in and get the job done so you can move on to building your amazing business.