What Is A Parquet File?
Data's like trash.
We make a lot of it. Then we squeeze more of it into smaller spaces.
Trash engineers optimize landfills. Data engineers optimize data storage... while making the data still accessible.
Thus Parquet was born.
While you ponder how to pronounce this exotic French word, those terabytes of data are compressed into a few GB of a Parquet file. And now it sits there, waiting for some lucky analyst to explore its mysteries.
Parquet files are the backbone of modern data engineering. They're a staple in data lakes and the foundation of other formats like Delta Lake and Iceberg. But few of us understand what a Parquet file is. Today we're changing that. Put your gloves on. We're going through the trash heap.
Storage Size
But first, a brief experiment. Let's put Parquet against the familiar CSV file. (Excel doesn't exist in my paradise.)
Here we have a Parquet file from the famous New York City Taxi dataset. We use the PyArrow package to read the Parquet file and convert it into a CSV file:
import pyarrow.parquet as pq
# read parquet file
file_path = "data/yellow_tripdata_2025-05.parquet"
parquet_file = pq.parquetFile(file_path)
# save as csv
df = parquet_file.read().to_pandas()
df.to_csv("data/yellow_tripdata_2025-05.csv", index=False)
Now, let's compare file sizes:
$ du -h data/yellow_tripdata_2025-05*
470M data/yellow_tripdata_2025-05.csv
75M data/yellow_tripdata_2025-05.parquet
Can you smell the savings? A 75 MB Parquet file is stored as a bloated 470 MB CSV file. Let's see how Parquet improves storage.
Structure of a Parquet File
"Parquet files keep data in columnar storage." You've heard that before. But what does it mean?
Think of a data table: there are rows and columns. This is 2-dimensional data. When you save a file, you need to convert the data into a one-dimensional stream of info. In a CSV file, data are stored by rows. That is, when you create the CSV file, rows are stored one after the other.
But with columnar storage, data is arranged differently. Data is stored a column at a time:
Said differently, with row-based storage, the "cells" of a row are placed next to each other. With column-based storage, the "cells" of a column are placed next to each other.
So what? Well say you need to compute the total sales across a table stored in CSV. You'd need to load each row into memory and find the column for sales; then you can total the sales. Even though you only need the sales column, all columns are loaded before the computation. But in Parquet, since all sales data are located next to each other (in a single column), you can jump to that portion of the file and ignore the other columns in the file. With less data to scan and process, the aggregation is faster for column-based storage compared to CSV's row-based storage.
Ready for some heartbreak? Parquet files are NOT stored in columnar storage. At least not pure columnar storage. Parquet uses a hybrid approach of row-based and column-based storage. Here's the hierarchy of objects in the Parquet format:
- Parquet files are made of row groups. These are chunks of records that are grouped together. Think of a row group as a mini-table.
- Within each row group, there are column chunks. Column chunks are saved in column-based storage arrangement.
- Within each column chunk, there are pages. Pages can hold the actual data or how the data is arranged.
Here's a demo showing our table in hybrid storage with row groups of size 2 (that is, 2 records per row group). Note how within each row group, columns are stored one after the other (i.e. columnar storage):
There's a bit more to the format, as outlined in the official Parquet docs:
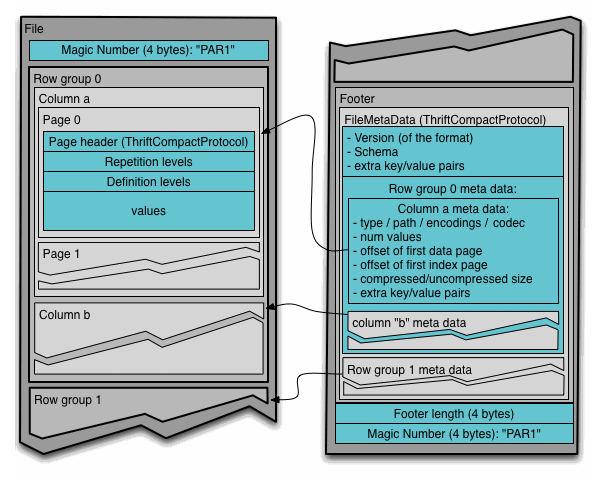
Near the end of the file, there's a footer filled with metadata. The footer lists the number of rows, schema (type of each column), and more metadata about each row group.
Side note: Metadata is "data about the data". It can include statistics like the max and min values, the number of rows, and the winning lottery numbers (kidding about that last one).
I have to gush over Parquet's built-in schemas. 😍 When loading CSV files, everything is text, and you later assign a data type to each column (integer, string, datetime, etc.). But with Parquet files, the type of each column is included in the file itself. You don't need a separate file (or some random guy in the application data department) to tell you what the schema is.
Storage Optimizations
Cool, now we see how data is stored in Parquet. But that doesn't explain how a Parquet file takes up less space than a CSV file. So far, we just rearranged the data from row-based to hybrid-based.
The obvious reason for smaller file size is compression (think zip files). The three most common compression algorithms are gzip, snappy, and zstd. Each algorithm has trade-offs between storage size and performance. In general, the more you compress a file, the more time it takes to unzip and process the file at query time. The outlier is zstd which has a good balance of storage size and performance.
But the real magic is how data is encoded to save disk space. "Encoding" means how the data is represented when it's sitting in storage. We'll check out 4 encoding methods.
1. Plain Encoding
Suppose we have a column of names: ["Harry", "Hermione", "Harry", "Harry", "Ron", "Hermione", "Ron", "Harry"] (Pretend this is a vertical column in a table.)
One way of saving this data is with plain encoding. That means the data is stored on disk the same way a human reads it in a table. Every instance of "Harry" takes up 5 bytes (one byte for each ASCII character). "Hermione" takes up 8 bytes, and each "Ron" occupies 3 bytes. But this is somewhat wasteful. The names repeat, and each instance of "Hermione" takes another 8 bytes.
2. Dictionary Encoding
An improvement over plain encoding is dictionary encoding. We give each name an ID number and record that once in a dictionary. Then, when encoding the column, we use the ID number instead of the name.
# option 1: plain encoding
column_chunk = ["Harry", "Hermione", "Harry", "Harry", "Ron", "Hermione", "Ron", "Harry"]
# option 2: dictionary encoding (define a dictionary and then encode values)
dictionary = {
0: "Harry",
1: "Hermione",
2: "Ron",
}
column_chunk = [0, 1, 0, 0, 2, 1, 2, 0] # <-- here we store IDs in the column chunk instead of names
This replaces a column of strings with a column of integers, which significantly saves space. Instead of storing the full name over and over, we store it once in the dictionary and then reference it with a much shorter integer every time the name appears.
Let's demonstrate the savings with a larger dataset. We have these three names appearing in a single column with 100,000,000 rows. We'll use PyArrow to save the table into two files: one with plain encoding and another with dictionary encoding:
import pyarrow.parquet as pq
import random
# make table with 100,000,000 names
people_options = ["Harry", "Hermione", "Ron"]
people = [random.choice(people_options) for _ in range(100_000_000)]
people_table = pa.table({"people": people})
# option 1: save with plain encoding
p.write_table(
people_table,
"data/people_plain.parquet",
use_dictionary=False,
column_encoding={
"people": "PLAIN", # force plain encoding
},
)
# option 2: save with dictionary encoding
pq.write_table(
people_table,
"data/people_dict.parquet",
use_dictionary=True, # try dictionary encoding
)
And now let's compare the file sizes:
$ du -h data/people*
25M data/people_dict.parquet
164M data/people_plain.parquet
The file with dictionary encoding is 85% smaller than the file with plain encoding! (25 MB vs 164 MB)
3. Run Length Encoding
Back to our toy example. But this time, our single-column table is sorted:
values_sorted = ["Harry", "Harry", "Harry", "Harry", "Hermione", "Hermione", "Hermione", "Hermione", "Hermione", "Hermione", "Ron", "Ron", "Ron", "Ron", "Ron", "Ron", "Ron", "Ron"]
With dictionary encoding, the long column can be stored like this:
# dictionary encoding
column_chunk = [0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2]
But do you see the repetition of IDs? What if we store each ID once and then record the number of times the ID repeats? That's run length encoding (RLE).
With RLE, a long sequence of repeated values is stored with just two numbers: the value and how many times it appears. Instead of writing 0 four separate times, 1 six separate times, etc, we use the more concise RLE representation:
# option 3: run length encoding
column_chunk = [(0, 4), (1, 6), (2, 8)] # template: (value, number of times it appears)
For that larger table with 100,000,000 rows, let's order the records and save as a 3rd file:
# save with run length encoding
sorted_people_table = pa.table({"people": sorted(people)})
pq.write_table(sorted_people_table, "data/people_sorted.parquet")
Drumroll please...
$ du -h data/people*
25M data/people_dict.parquet
164M data/people_plain.parquet
20K data/people_sorted.parquet
20 kilobytes. 🤯 The sorted column takes up 20 kilobytes, 0.01% the space of the plain-encoded file and 0.08% of the dictionary-encoded file.
What's the take away here? Please, for the love of Codd, sort your data before you save it.
4. Delta Encoding
One more: delta encoding works best for ordered, numeric columns. Instead of storing tons of large numbers, you store the first large number; all other numbers are stored as the difference (or delta) between that number and the previous one.
A good use case is the timestamp data type. Timestamps represent time as the number of seconds since January 1, 1970 00:00 UTC. For example, the timestamp 1754399851 represents the time "August 5, 2025 at 8:17:31 AM."
Below, we have 5 timestamps in ascending order. Look at the two encoding styles. In plain encoding, we have to store many large integers. With delta encoding, the small difference between each value and the one that comes before is stored in fewer bits, saving storage.
| Timestamps | Plain Encoding | Delta Encoding |
|---|---|---|
| 1754399851 | 1754399851 | 1754399851 |
| 1754399855 | 1754399855 | 4 |
| 1754399857 | 1754399857 | 2 |
| 1754399859 | 1754399859 | 2 |
| 1754399860 | 1754399860 | 1 |
Let's demonstrate again with a larger table of a million timestamps:
from datetime import datetime
# create table with 1 million timestamps
timestamps = [datetime.now() for _ in range(1_000_000)]
ts_table = pa.table({"timestamps": timestamps})
# option 1: save with plain encoding
pq.write_table(
ts_table,
"data/timestamps_plain.parquet",
compression=None,
use_dictionary=False,
column_encoding={
"timestamps": "PLAIN", # force plain encoding
},
)
# option 2: save with delta encoding
pq.write_table(
ts_table,
"data/timestamps_delta.parquet",
compression=None,
use_dictionary=False,
column_encoding={
"timestamps": "DELTA_BINARY_PACKED", # try delta encoding
},
)
Now let's compare the file sizes:
$ du -h data/timestamps*
256K data/timestamps_delta.parquet
7.7M data/timestamps_plain.parquet
Storing all those timestamps as long integers takes 7.7 MB. But using delta encoding reduces the size to 256 KB, or 3.2% of the original size!
Okay, we finished our journey through Parquet storage patterns.
To be fair, PyArrow and Parquet have more advanced optimizations than what we saw here. But I hope these examples show you how powerful encoding techniques can be.
Most of the time, you don't need to worry about encoding style. Processing tools like Spark, PyArrow, and BigQuery will intelligently choose the best encoding and compression algorithm for the particular dataset. But sometimes you know better. And when that's true, you can force a particular storage pattern that meets your needs.
Here's the cheatsheet on when to use each column encoding:
- Plain Encoding: When there's just nothing better.
- Dictionary Encoding: When there are a few unique values that appear a lot. (The math boys call this "low cardinality.")
- Run Length Encoding: When there are runs of repeated values.
- Delta Encoding: When there are large numbers that are sorted and increasing slowly.
The Parquet format efficiently stores large datasets and is the defacto standard today. There are additional features that enable high performance when analyzing data in Parquet files... but that's a post for another day. If you're a nerd like me who likes to have a good time, go read the docs.
Is your cloud storage bill too high due to the pile of Parquet files? Do you need help optimizing your data lake? Call me. My trash truck is ready to clear your digital neighborhood.